Workshop: Build serverless edge applications with Cloudflare Workers and Fauna
In this workshop, you’ll learn how to build a distributed serverless application using Cloudflare Workers and Fauna.
The example app uses Fauna and Cloudflare Workers Cron Triggers to:
-
Fire a Workers function that connects to Fauna. The function confirms the Worker has access to a cursor value. The cursor records the last time the function was run.
-
Connect to a Fauna event feed of e-commerce orders, getting events since the last cursor.
-
Use a webhook to push order information from the event feed to a fulfillment application.
-
Write the resulting cursor value to Fauna for use in the next Workers function run.
Why Cloudflare Workers and Fauna?
Cloudflare Workers are serverless functions that run on Cloudflare’s edge network. They are written in JavaScript, TypeScript, Rust, or Python and can be used to build serverless applications that run close to your users, reducing latency and improving performance.
Fauna is a globally distributed, low-latency, strongly consistent, and serverless database. It is designed to work well with serverless functions like Cloudflare Workers and provides a powerful and flexible data platform for building modern applications.
Fauna is a database delivered as an API. Fauna is globally distributed. Your data is always close to your users, reducing latency and improving performance.
By combining Cloudflare Workers and Fauna, you can build serverless applications that are fast, reliable, and scalable, with low operational overhead.
Prerequisites
-
A Cloudflare account
-
Node.js v20.x or later installed on your local machine
-
Fauna CLI v4 installed on your machine with an access key
-
Some familiarity with Cloudflare Workers and Fauna
Creating the Cloudflare Worker
-
Install Cloudflare Wrangler:
npm install -g wrangler@latestEnsure Cloudflare Wrangler is v3.88 or higher.
-
Create a new Cloudflare Worker project:
npm create cloudflare -- my-fauna-worker cd my-fauna-workerWhen running
npm create cloudflare ..., you’re prompted with multiple questions. When asked which example and template, choose the "Hello World" one.For language, choose "TypeScript". When it asks if you want to deploy your application, select "No".
-
Set up cron triggers in
wrangler.toml:cat <<EOF >> wrangler.toml [triggers] crons = [ "*/30 * * * *" ] EOF -
Using the wrangler CLI, deploy the Worker to register it in Cloudflare.
wrangler deploy -
Open the newly created project in your favorite code editor.
Create a Fauna Database
You can create a new database from the Fauna Dashboard or using the Fauna CLI. For this workshop, we will create a new database using the Fauna Dashboard.
-
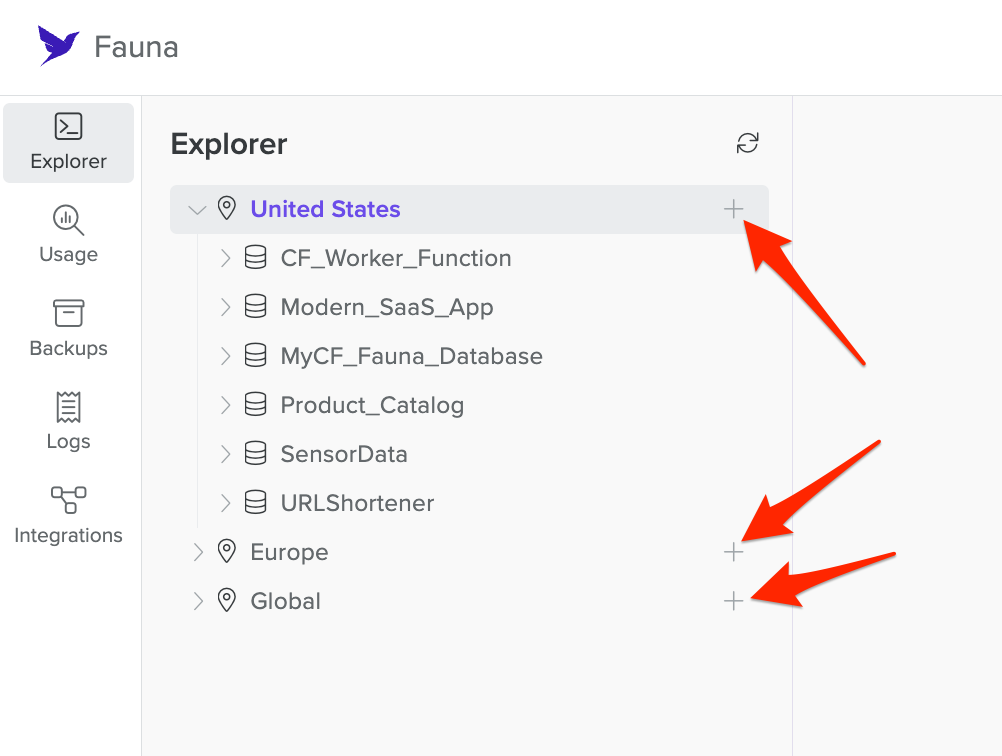
Log into the Fauna Dashboard.
-
Choose the Region group you want the database to be created in, and click the + button for that region.
-
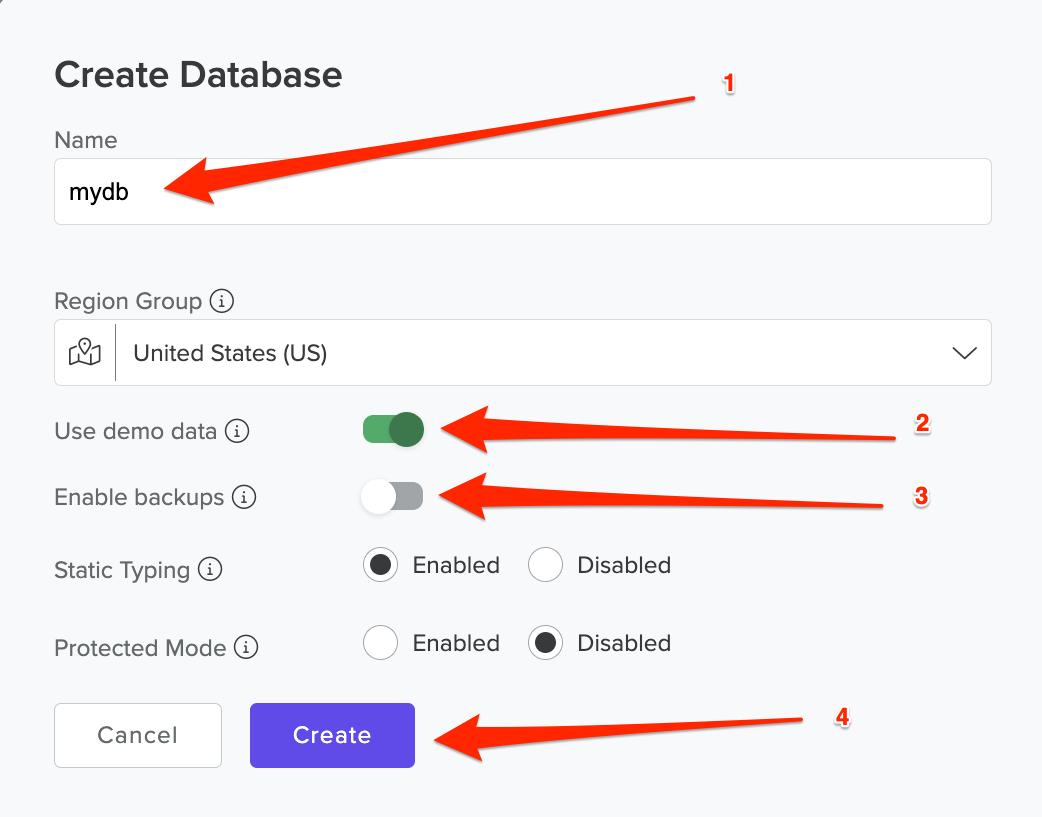
Name the database mydb, enable the Use demo data option, enable/disable Backups, and click Create.
Modify the database schema to add a locking mechanism
Next, modify the schema to add new collections, roles, and user-defined
functions (UDFs) to the demo database. The app uses the Lock collection to
ensure that only one Cloudflare Worker function is processing the Fauna event
feed at a time.
-
Create a schema directory:
mkdir schema && cd schema -
If you haven’t already, log in to Fauna using the CLI:
fauna login -
Pull the existing demo schema:
fauna schema pull --database us-std/mydb -
Add the following to the end of
collections.fsl:... collection Cursor { name: String cursorValue: String? *: Any unique [.name] index byName { terms [.name] } } collection Lock { name: String cursorInfo: Ref<Lock>? locked: Boolean = false *: Any unique [.name] document_ttls true index byName { terms [.name] } }Lockdocuments have alockedfield. The field ensures only one Cloudflare Worker function is processing the order event feed at a time.Cursorcollection documents have acursorValuefield that stores the cursor for the last event feed page processed. The next Worker function call gets events after this cursor. The setup is serverless and region-agnostic. -
Add the following to the end of
functions.fsl:role locksAndCursors { privileges Cursor { create read write } privileges Lock { create read write } } @role(locksAndCursors) function lockAcquire(name, identifier) { let lock = Lock.byName(name + "Lock")!.first() // If locked is true, then we need if we are the ones who own the lock if ((lock != null) && (lock!.locked == true)) { // if the lock document exists and is locked by someone else, return the value of locked // and the identity of who has it locked currently. lock {locked, identity, test: "dfd"} } else if ((lock != null) && (lock!.locked == false)) { // If the lock document exists and is not locked, lock it, set a TTL on the document, and the cursor. lock!.update({locked: true, identity: identifier, ttl: Time.now().add(6000, "seconds"), cursor: Cursor.byName(name + "Cursor")!.first()}) } else if (lock == null) { //if the document doesn't exist, create it, and lock set it to locked by the calling function. Lock.create({ name: name + "Lock", locked: true, identity: identifier, lastProcessedTimestamp: Time.now(), cursor: Cursor.byName(name + "Cursor")!.first(), ttl: Time.now().add(600, "seconds") }) } } @role(locksAndCursors) function lockUpdate(name, cursorValue) { let lock = Lock.byName(name + "Lock")!.first() // If the document is locked, set `locked` to false, update the `lastProcessedTimestamp`, and remove `ttl` field if (lock != null && lock!.locked == true) { // if lock!.update({locked: false, lastProcessedTimestamp: Time.now(), ttl: null, identity: null}) Cursor.byId(lock!.cursor.id)!.update({value: cursorValue}) } else { //if nothing else, abort. abort("Invalid document id or lock not set.") } }The schema defines a role and two UDFs.
The
lockAcquire()UDF acquires a lock and cursor. ThelockUpdate()releases the lock after processing the event feed.The
lockAndCursorsrole grants the minimum privileges required to call the UDFs and perform CRUD operations on theLockandCursorcollections. -
Push the schema to Fauna:
fauna schema push --database us-std/mydbWhen prompted, accept and stage the schema.
-
Check the status of the staged schema:
fauna schema status --database us-std/mydb -
When the status is
ready, commit the staged schema to the database:fauna schema commit --database us-std/mydbThe commit applies the staged schema to the database.
Integrating Fauna with Cloudflare Workers
You can integrate Fauna using the Cloudflare dashboard or the Wrangler CLI. For this workshop, use the Cloudflare dashboard and the native Fauna integration.
-
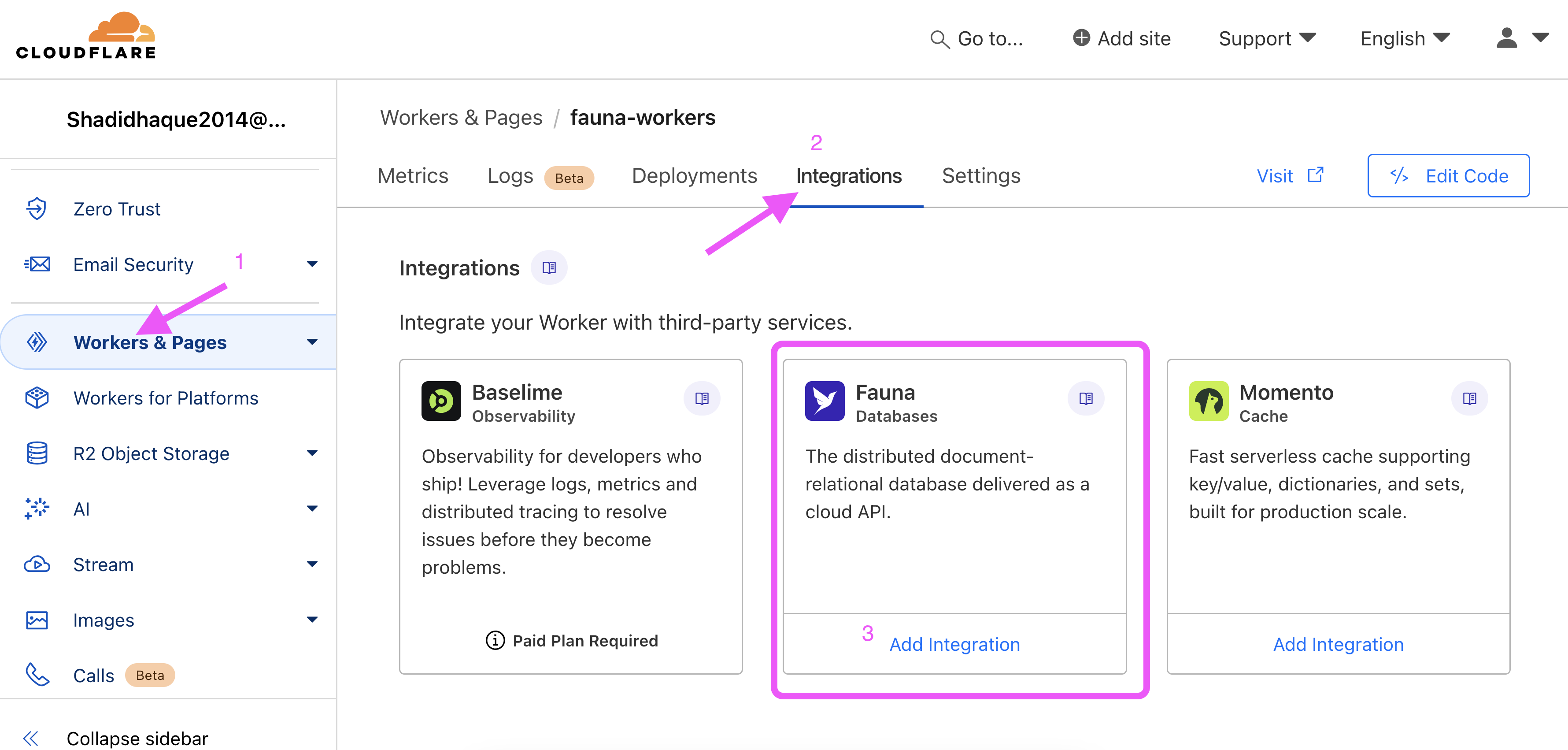
Open the Cloudflare dashboard and navigate to the Workers & Pages section.
-
Select the my-fauna-worker Worker you created earlier.
-
Select the Integrations tab.
-
Under Fauna, select Add Integration and authenticate with your existing Fauna account.
-
When prompted, select the Fauna database you created earlier.
-
Select a database security role. For this workshop, you can select the server role. For a production deployment, you should create a custom role before this step.
Accessing data from Fauna in Cloudflare Workers
You can use a Fauna client driver to access data from Fauna in a Cloudflare Worker.
Using a driver is the easiest way to interact with Fauna databases from Cloudflare Workers. Each driver is a lightweight wrapper for the Fauna Core HTTP API.
For this workshop, use the JavaScript driver:
-
Install the Fauna JavaScript driver in your Cloudflare Worker project. Also install the
uuidlibrary.npm install fauna npm install uuid -
Replace the contents of
src/index.tswith the following:import { Client, fql, FaunaError, FeedClientConfiguration, ServiceError } from 'fauna'; import { v4 as uuidv4 } from 'uuid'; export interface Env { FAUNA_SECRET: string; } export default { async scheduled( request: ScheduledEvent, env: Env, ctx: ExecutionContext ): Promise<void> { // Extract the method from the request. const { method } = request; // Instatiate a Fauna client instance. const client = new Client({ secret: env.FAUNA_SECRET }); try { // There are two cursors used in the code. The first is for where in the Fauna feed to pick up from. // the second is for the document stored in Fauna that is used for locking the feed so it's only processed // one at a time by a single Worker. const myIdentifer = uuidv4().toString(); //generate a unique identifier for this function run. // Call the lockAcquire user-defined function in Fauna to get the cursor information, // lock information, and if you can lock it, append the identity. const lockDataResponse = await client.query( fql`lockAcquire("orderFulfillment", ${myIdentifer})` ); // The response from the UDF is a JSON object with a data field containing the cursor //information and stats. We need the data part only for this example. const lockData = lockDataResponse.data; // If locked is true and the identity field doesn't match, return 409. if ((lockData.locked) && ('identity' in lockData) && !(lockData.identity == myIdentifer)) { return new Response('Another Worker is processing the feed', { status: 409 }); } else if (lockData.locked == true && lockData.identity == myIdentifer) { // Got the lock. Process the Fauna event feed. const cursorValue = await client.query( fql`Cursor.byId(${lockData.cursor.id}) { cursorValue }` ); // Get the value of the cursor. let cursorVal: string | null = cursorValue.data?.cursorValue; const options = cursorVal ? { cursor: cursorVal } : undefined try { // Get an event feed for the `Order` collection. const feed = client.feed(fql`Order.all().eventSource()`, options); for await (const page of feed) { console.log("Page: ", page); // You need to make a decision here if you want to // flatten the events. This example does not. cursorVal = page.cursor; for (const event of page.events) { console.log("Event: ", event); cursorVal = event.cursor; console.log("event cursor: " + cursorVal); switch (event.type) { case "add": // Webhook to add a new order in the fulfillment system //console.log("Add event: ", event); break; case "update": // Webhook to update an order in the fulfillment system console.log("Update event: ", event); break; case "remove": // Webhook to attempt to cancel an order in the fulfillment system console.log("Remove event: ", event); break; } } // Update the cursor in Fauna. const updateCursor = await client.query( fql`Cursor.byId(${lockData.cursor.id})!.update({ cursorValue: ${page.cursor} })` ); } console.log(cursorVal); // Release the lock. await client.query( fql`lockUpdate("orderFulfillment", ${cursorVal})` ); return new Response('I got the lock and then did some stuff!', { status: 200 }); } catch (cursorError) { if (cursorError instanceof FaunaError && cursorError.message.includes("is too far in the past")) { console.warn("Cursor is too old, deleting and retrying..."); // Delete the outdated cursor document. await client.query( fql`Cursor.byId(${lockData.cursor.id})!.update({cursorValue: null})` ); // Unlock the lock document. await client.query( fql`lockUpdate("orderFulfillment", ${cursorVal})` ); } else { throw cursorError; } } } else { return new Response('There is nothing to do, something went wrong.', { status: 500 }); } } catch (error) { if (error instanceof FaunaError) { if (error instanceof ServiceError) { console.error(error.queryInfo?.summary); } else { return new Response("Error " + error, { status: 500 }); } } return new Response('An error occurred, ' + error.message, { status: 500 }); } }, };
Define data relationships with FSL
To show off the Cloudflare Cron Trigger and the cursor and lock collections we
created above, we’ll use three collections in the Fauna demo database:
Order, OrderItem, and Product.
Every order has one or more order items, and each order item has one product
related to it. When creating an OrderItem document, it relates a product to an
order.

In addition, you see the items field in the Order collection. This is a
computed field. When you read the Order
document, Fauna will return an array of all products that are part of the order.
Document-relational model
Fauna supports both document and relational data patterns, making it suitable for a wide range of use cases.
In the example above, we demonstrated how to define relationships using
Fauna Schema Language (FSL). You can think of the
Cursor and Lock collections as representing a typical relational model
(one-to-one), where cursors are linked to locks.
What makes Fauna unique is its capability to perform relational-like joins within a document-based system.
Now, let’s look at a many-to-many relationship using Fauna’s document-relational capabilities.
Add orders and items to an order
-
Create a document in the
Ordercollection. Then add an item to the order.// Create a new order document in the Order collection, but save the order ID. let order = Order.create({ customer: Customer.byId(111), status: "processing", createdAt: Time.now() }) // Create a new order item document in the OrderItem collection and relate it to the order with the ID // from the previous step. OrderItem.create({order: order, product: Product.byName("pizza").first(), quantity: 1})As you can see, Fauna provides you SQL-like relational capabilities while maintaining the flexibility of a document-based database. The
OrderItemdocument to relationships with a Product and one with the Order. Then in every order document, there is a field calleditemsthat contains an array ofOrderItemdocuments. This is a many-to-many relationship. If you do a projection on that field, you will get an array of the items in the order because of the generateditemsfield.Learn more about data relationships in Fauna.
Test the application
Deploy the Cloudflare Worker
-
Deploy the Cloudflare Worker:
wrangler deploy -
Test the Cloudflare Worker by creating a new order.
// Create a new order document in the Order collection, but save the order ID. let order = Order.create({ customer: Customer.byId(111), status: "processing", createdAt: Time.now() }) // Create a new order item document in the OrderItem collection and relate it to the order with the ID // from the previous step. OrderItem.create({order: order, product: Product.byName("cups").first(), quantity: 1})
You can find the full source code for this workshop in the following GitHub repository.