Query data with FQL
| Reference: FQL language reference, FQL API reference |
|---|
Fauna Query Language (FQL) is a TypeScript-like language used to read and write data in Fauna. You can use FQL to build type-safe, composable queries that combine the flexibility of JSON-like documents with the safety of static typing.
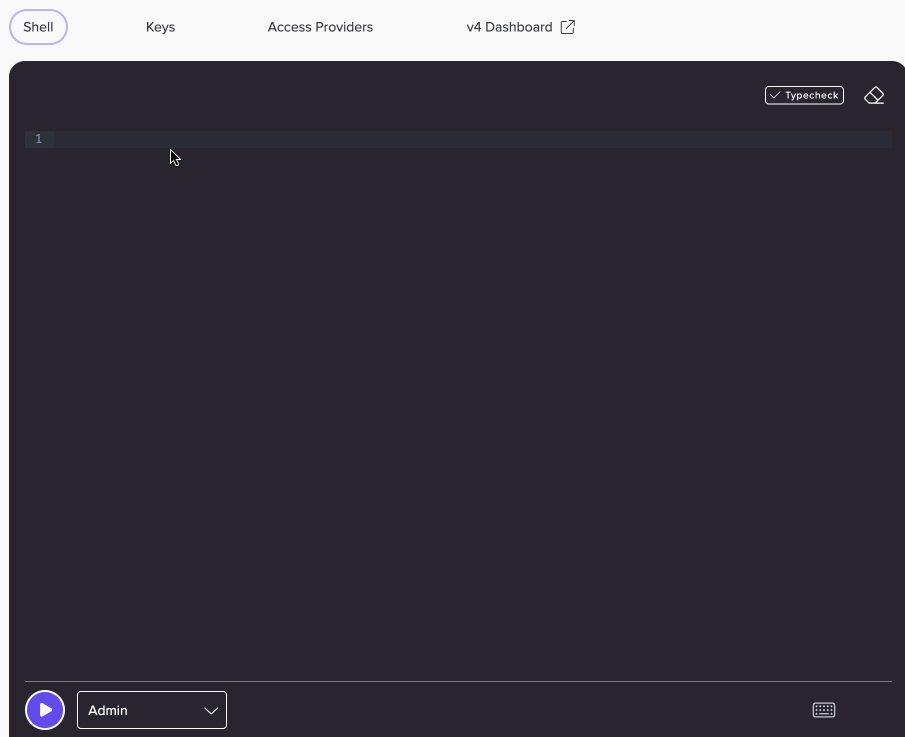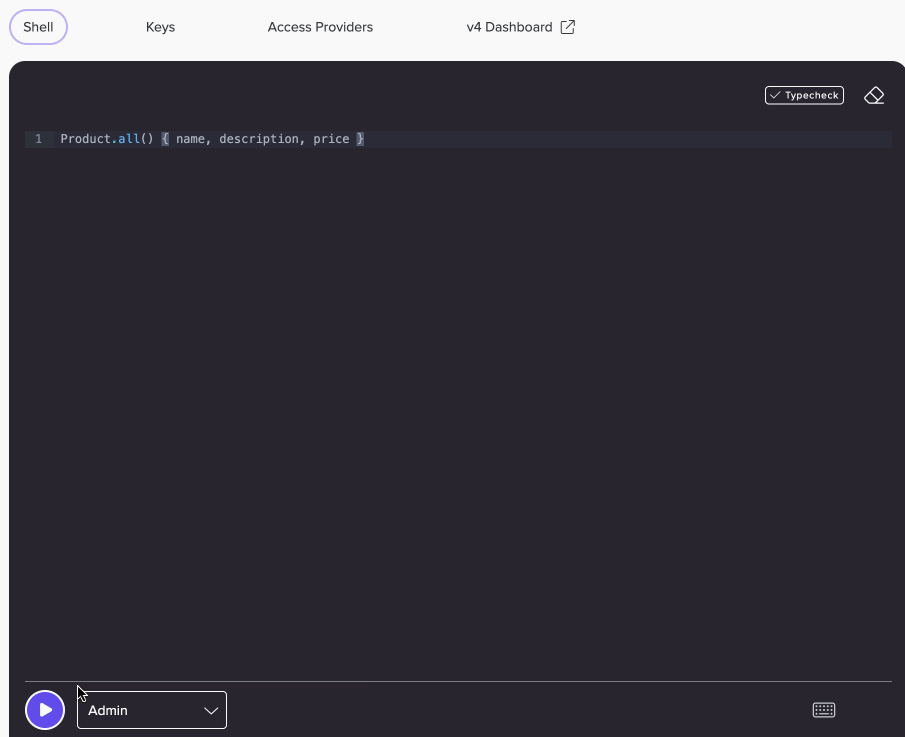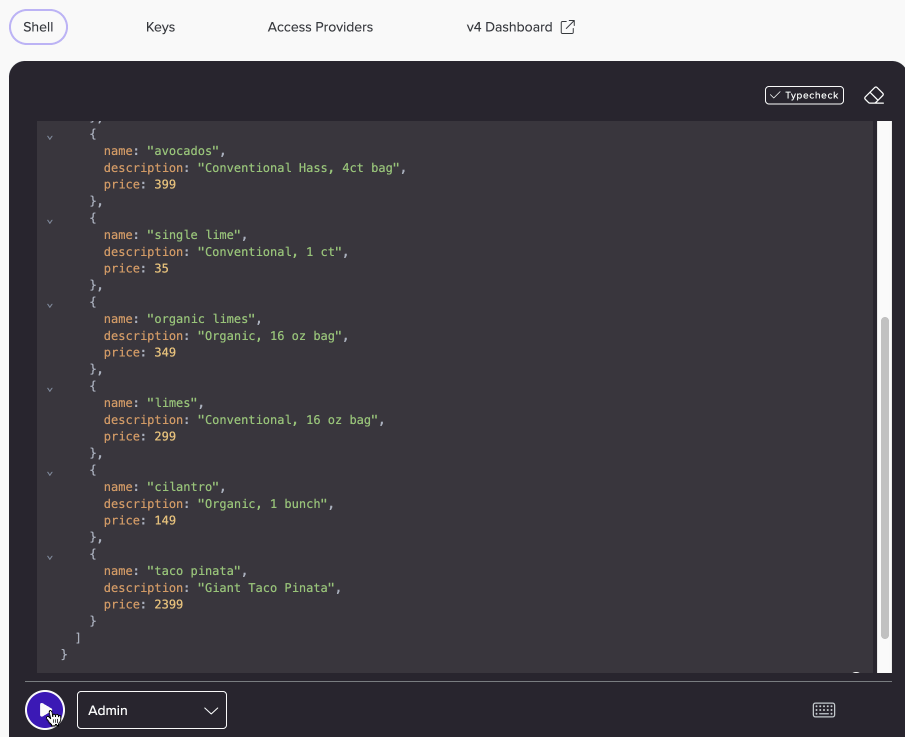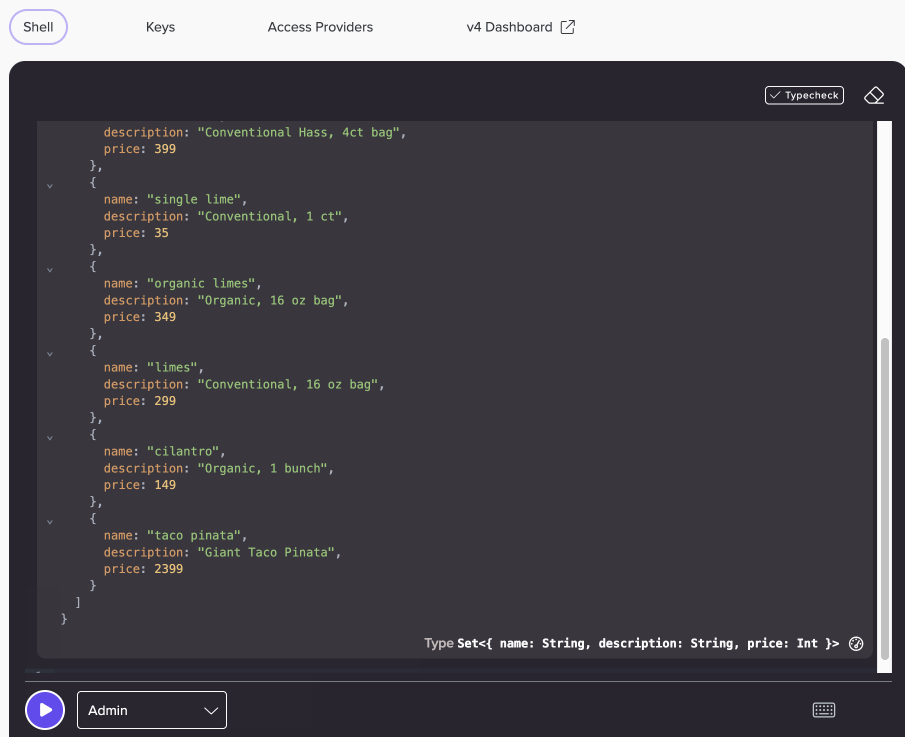
// Calls the `all()` method on the `Product` collection.
// Returns the `name`, `description`, and `price` fields of
// all `Product` collection documents.
Product.all() { name, description, price }Fauna stores data as JSON-like documents, organized into collections. Queries can filter and fetch documents from a collection as a set, and iterate through each document.
Run queries
HTTP API and client drivers
In an application, you typically run queries by working directly with the Fauna Core HTTP API or using a Fauna client driver for your preferred programming language:





Fauna Dashboard
For testing or one-off queries, you can use the Fauna Dashboard Shell to run FQL queries:
Fauna CLI
You can also use the Fauna CLI to run FQL queries from files or in an interactive REPL.

| See Fauna CLI v4 |
|---|
Basic operations
For a examples of covering basic operations using FQL queries, including document CRUD operations, see CRUD and basic operations. For other common FQL query patterns, see FQL query patterns.
|
For a quick reference of FQL methods, check out the FQL cheat sheet. |
Method chaining
You typically compose an FQL query by chaining methods to one or more collections. Expressions are evaluated from left to right.
// `firstWhere()` gets the first `Product` collection document with
// a `name` of `cups`. `update()` updates the document's `name`
// field value to `clear cups`. The `?.` operator only calls
// `update()` if `firstWhere()` returns a non-null value.
Product.firstWhere(.name == "cups")?.update({ name: "clear cups" })| See Field accessors and method chaining |
|---|
Static typing
FQL is statically typed. Every expression has a data type that’s checked before evaluation. If Fauna detects a type mismatch, it rejects the query with an error.
Type checking helps catch errors early and consistently, saving you time during development.
| See Static typing |
|---|
Indexes
An index stores, or covers, specific document field values for quick retrieval.
You can use indexes to filter and sort a collection’s documents in a performant way. Unindexed queries should be avoided.
| See Indexes |
|---|
Relationships
You create relationships by including a reference to a document in another document. This lets you model complex data structures without duplicating data across collections.
// Get a `Category` collection document.
let produce = Category.byName("produce").first()
// Create a `Product` collection document that references
// the `Category` collection document in the `category` field.
Product.create({
name: "key lime",
description: "Organic, 1 ct",
price: 79,
category: produce,
stock: 2000
})| See Model relationships using document references |
|---|
Projection
Projection lets you return only the specific fields you want from queries.
You can project results to dynamically resolve document relationships. This lets you resolve multiple deeply nested relationships in a single query.
// Uses projection to only return each document's `name`,
// `description`, and `category` fields. The `category` field
// contains a resolved `Category` collection document.
Product.byName("key lime") { name, description, category }| See Projection and field aliasing |
|---|
Pagination
Fauna provides pagination for queries that return large datasets. Fauna client drivers include methods for iterating through paginated query results.
| See Pagination |
|---|
Query composition
The Fauna client drivers compose queries using template strings. You can interpolate variables, including other FQL template stings, to build dynamic queries.
For example, using the JavaScript driver:
import { Client, fql } from "fauna";
const client = new Client({
secret: 'FAUNA_SECRET'
});
const minPrice = 5_00;
const maxPrice = 50_00;
const query = fql`
Product.where(.price >= ${minPrice} && .price <= ${maxPrice})
`;
let response = await client.query(query);
console.log(response.data);
client.close();| See Query composition |
|---|
Performance hints
Performance hints provide actionable steps for improving an FQL query’s performance. You typically use performance hints when testing or prototyping queries in the Fauna Dashboard Shell.

| See Performance hints |
|---|